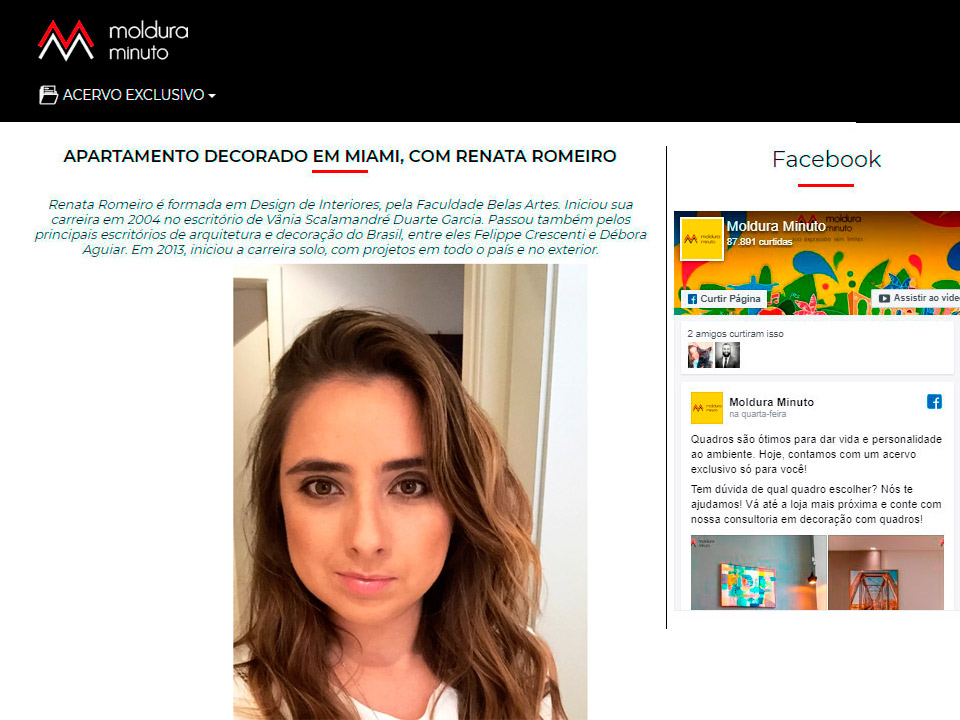
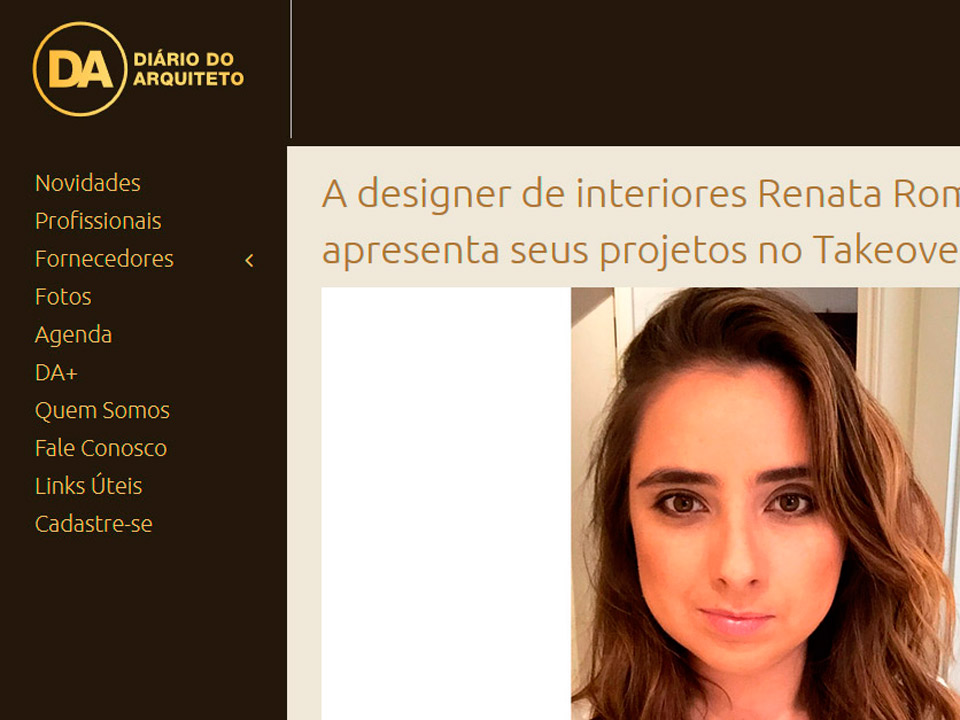
pytorch distributed training example github
Go To GitHub. Also a dataset.py to load dataset in common scenarios. WebDataset. The data parallel feature in this library is a distributed data parallel training framework for PyTorch, TensorFlow, and MXNet. Total running time of the script: ( 0 minutes 0.000 seconds) Download Python source code: trainingyt.py. The TorchTrainer is a wrapper around torch.distributed.launch with a Python API to easily incorporate distributed training into a larger Python application, as opposed to needing to wrap your training code in bash scripts.. For end to end examples leveraging RaySGD TorchTrainer, jump to TorchTrainer Examples. *Installation: * Use pip/conda to install the following libraries - torch - torchvision - argparse - tqdm *Run using: * `python torch_distributed.py -g 4 --batch_size 128` where,-g: no. Distributed Training¶ Note: You can find the example script of this section in this GitHub repository. ). MPI through mpi-operator. Prerequisites: PyTorch Distributed Overview; RPC API documents; This tutorial uses two simple examples to demonstrate how to build distributed training with the torch.distributed.rpc package which was first introduced as an experimental feature in PyTorch v1.4. Useful especially when scheduler is too busy that you cannot get multiple GPUs allocated, or you need more than 4 GPUs for a single job. It means that I want to train my model with 8*N GPUs. More detailed information and examples are available at its Github repo. ddp_mnist_torch: An example showing how to use DistributedDataParallel with Ray Tune. Omikuji ⭐ 63. x x (a 2D mini-batch Tensor ) and output. Pin each GPU to a single process. Example of PyTorch DistributedDataParallel. Source Distribution. In my case, the DDP constructor is hanging; however, NCCL logs imply what appears to be memory being allocated in the underlying cuda area (? PyTorch distributed GPU training with NVIDIA Apex . We have trained the network for 2 passes over the training dataset. multiprocessing as mp: from torch. 2. PyTorch-Distributed-Training. The data parallel feature in this library (smdistributed.dataparallel) is a distributed data parallel training framework for PyTorch, TensorFlow, and MXNet.. Preparations. everybody knows,mnistLearn on computer vision, just likehello worldFor major programming languages, I believe that many friends look at each depth learning framework, they all look at the training.mnistExample, for examplePyTorch of mnist example,TensorFlow of mnist example. Note: When performing distributed training with BF16 data type, please use oneCCL Bindings for Pytorch*. so,mnistFor the depth learning framework, it is a good opportunity to peek in the tube. 2. Distributed training is an increasingly common and important deep learning technique, as it enables the training of models too big or too cumbersome to manage on a single machine. First, DataParallel is single-process, multi-thread, and only works on a single machine, while DistributedDataParallel is multi-process and works for both single- and multi- machine training. utils. Multi-node distributed training, DDP constructor hangs. Distributed Training by Pytorch. Tutorials on GitHub. The related code is available here. Distributed data parallel training in Pytorch Edited 18 Oct 2019: we need to set the random seed in each process so that the models are initialized with the same… yangkky.github.io Also, look at part 2 where we'll add additional features to our toolset. See the examples folder for notebooks you can download or run on Google Colab.. Overview¶. Apex is currently supported by Amazon EC2 instances in the following families: Migrate to PyTorch v1.1.0 ( #15) 3 years ago. Here, pytorch:1.5.0 is a Docker image which has PyTorch 1.5.0 installed (we could use NVIDIA's PyTorch NGC Image), --network=host makes sure that the distributed network communication between nodes would not be prevented by Docker containerization. retinaface_pytorch-..8-py2.py3-none-any.whl (26.8 kB view hashes ) Uploaded Jan 24, 2022 . ''' Multi machine multi gpu. For example, if you want to use 2 nodes and 4 GPUs per node, then 2*4 =8 processes will be . PyTorch: Tensors ¶. Django Bootstrap SQLite. Distributed data parallel training using Pytorch on the multiple nodes of CSC and Narvi clusters Table of Contents. But we need to check if the network has learnt anything at all. Process: An instance of the python. Establishes connectivity between them necessary for Pytorch and Pytorch Lightning distributed training; . For more information on the utilities offered with Apex, see the NVIDIA Apex website. Warning: might need to re-factor your own code. Asciotti53 (Andrew Sciotti) March 17, 2022, 6:37pm #1. distributed as dist: import torch. import torch: import torch. A set of examples around pytorch in Vision, Text, Reinforcement Learning, etc. Training procedure example. Here we introduce the most fundamental PyTorch concept: the Tensor.A PyTorch Tensor is conceptually identical to a numpy array: a . ). First, DataParallel is single-process, multi-thread, and only works on a single machine, while DistributedDataParallel is multi-process and works for both single- and multi- machine training. PyTorch Distributed Data Parallel (DDP) example. GitHub Gist: instantly share code, notes, and snippets. For modern deep neural networks, GPUs often provide speedups of 50x or greater, so unfortunately numpy won't be enough for modern deep learning.. - History for distributed - pytorch/examples Node: A node is the same. However, the rest of it is a bit messy, as it spends a lot of time showing how to calculate metrics for some reason before going back to showing how to wrap your model and launch the processes. Windowed aggregations using spark streaming and ingestion to the online feature store. elastic. of gpus Learn more about bidirectional Unicode characters. Distributed, mixed-precision training with PyTorch. Horovod Ansible ⭐ 21. This is the ' 'fastest way to use PyTorch for either single node or ' 'multi node data parallel training') best_acc1 = 0: def main (): args = parser. To fix this issue, find your piece of code that cannot be pickled. Let's discuss some definitions first. NVIDIA Apex is a PyTorch extension with utilities for mixed precision and distributed training. We will discuss two techniques that can be used for distributed computing with PyTorch. Data parallel distributed BERT model training with PyTorch and SageMaker distributed . In PyTorch, distributed training using torch.dist.DistributedParallel, the number of spawned processed equals to the number of GPUs you want to use. add_argument ('--multiprocessing-distributed', action = 'store_true', help = 'Use multi-processing distributed training to launch ' 'N processes per node, which has N GPUs. Hi all, I am trying to get a basic multi-node training example working. training script to each node separately, we need to set a random seed to fix the randomness involved in the code. 1. The first process on the server will be allocated the first GPU, the second process will be allocated the second GPU, and so forth. To review, open the file in an editor that reveals hidden Unicode characters. Let's quickly save our trained model: PATH = './cifar_net.pth' torch.save(net.state_dict(), PATH) See here for more details on saving PyTorch models. Training an image classifier. The end of the stacktrace is usually helpful. A set of examples around pytorch in Vision, Text, Reinforcement Learning, etc. update docs to point to pytorch 1.9 and torchx for torchelastic and t…. WebDataset is a PyTorch Dataset (IterableDataset) implementation providing efficient access to datasets stored in POSIX tar archives and uses only sequential/streaming data access. Distributed Data-Parallel Training (DDP) is a widely adopted single-program multiple-data training paradigm. Failed to load latest commit information. You may also want to try out PyTorch Lightning which has a simple API for multi-node training: . Large Scale Pretraining Transfer ⭐ 3. First, training is tested in a local environment with SageMaker local mode and then moved to the cloud. Numpy is a great framework, but it cannot utilize GPUs to accelerate its numerical computations. The utility can be used for single-node distributed training, in which one or more processes per node will be spawned. . ie: in the stacktrace example here, there seems to be a lambda function somewhere in the code which cannot be pickled. For licensing details, see the PyTorch license doc on GitHub. hierarchical-multi-label-text-classification-pytorch. Distributed Pytorch ⭐ 22. master/imagenet. Author: Shen Li. Pytorch Distributed Example Requirements References. The Tutorials section of pytorch.org contains tutorials on a broad variety of training tasks, including classification in different domains, generative adversarial networks, reinforcement learning, and more. It starts from a toy PyTorch Lightning application (training ResNet-18 on CIFAR-10) and then describes the necessary steps for running it on SageMaker. Initialize multiprocessing environment with gloo back-end. It provide you a powerful engine.py which can do lot of training functionalities. Before we dive in, let's clarify why, despite the added complexity, you would consider using DistributedDataParallel over DataParallel:. Download files. In this example we showed how to train a distributed PyTorch lighting model in the next post we will show how to deploy the model as an AKS service. The extension supports FP32 and BF16 data types. We will do the following steps in order: Load and normalize the CIFAR10 training and test datasets using torchvision. PyTorch Distributed Overview; . Create training dataset from online feature store enabled feature groups. As of PyTorch v1.6.0, features in torch.distributed can be categorized into three main components:. Source code of the two examples can be found in PyTorch examples. Walk through an end-to-end example of training a model with the C++ frontend by training a DCGAN - a kind of generative model - to generate images of MNIST digits. Test the network on the test data. How and where to deploy models - Azure Machine . This backend is not optimized for distributed GPU training but, if you want to use CPU as distributed environment, use gloo.And don't forget to setting MASTER_ADDR and MASTER_PORT to your . This enables both distributed training and distributed hyperparameter tuning. 4. Note: - Pytorch Trainer is not a distributed training script. pytorch / elastic Public. This library contains 9 modules, each of which can be used independently within your existing codebase, or combined together for a complete train/test workflow. Numpy is a great framework, but it cannot utilize GPUs to accelerate its numerical computations. RPC is the only way to support model . Also shows how to easily convert something relying on argparse to use Tune. 3. With the typical setup of one GPU per process, set this to local rank. pytorch_lightning_distributed_training.py. It works by skipping each num_workers * world_size element, starting at index rank + num . . Tutorial Code for distributed training in PyTorch that trains : an inception_v3 model on dummy data. Cutting edge deep learning models are growing at an exponential rate: where last year's GPT-2 had ~750 million parameters, this year's GPT-3 has 175 billion. Distributed model training in PyTorch using DistributedDataParallel. import multiprocessing. View code. Junwu_Weng (TechWuere) September 26, 2019, 7:37am #1. import os. Parallel and Distributed Training. torch.distributed.launch is a module that spawns up multiple distributed training processes on each of the training nodes. 5. This article attempts to answer this question for distributed data-parallel training. PyTorch: Tensors ¶. make examples README.md in actual markdown format (was in rst . Define a Convolutional Neural Network. suppose we have two machines and one machine have 4 gpus Public. This notebook demonstrates how to use the SageMaker distributed . For modern deep neural networks, GPUs often provide speedups of 50x or greater, so unfortunately numpy won't be enough for modern deep learning.. With DDP, the model is replicated on every process, and every model replica will be fed with a different set of input data samples. I am going to train my model on multi-server (N servers), each of which includes 8 GPUs. Usually we don't need distributed training and it is very uncomfortable to use argparse and get the job done. This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. PyTorch project is a Python package that provides GPU accelerated tensor computation and high level functionalities for building deep learning networks. Apache MXNet through mxnet-operator. The utility can be used for either CPU training or GPU training. Kubeflow training is a group Kubernetes Operators that add to Kubeflow support for distributed training of Machine Learning models using different frameworks, the current release supports: TensorFlow through tf-operator (also know as TFJob) PyTorch through pytorch-operator. If the utility is used for GPU training . Getting Started with Distributed RPC Framework¶. For example, this official PyTorch ImageNet example implements multi-node training but roughly a quarter of all code is just boilerplate engineering for adding multi-GPU support: Setting CUDA devices, CUDA flags, parsing environment variables and CLI arguments, wrapping the model in DDP, configuring distributed samplers, moving data to the . Train the network on the training data. 1. This simplifies the training. GPT is a somewhat extreme example; nevertheless, the "enbiggening" of the SOTA is driving larger and larger models . Download the file for your platform. parse_args if . OUTLINE Installation Example Job Data Loading using Multiple CPU-cores GPU Utilization Distributed Training or Using Multiple GPUs Building from Source Containers Working Interactively with Jupyter on TigerGPU Automatic Mixed Precision (AMP) PyTorch Geometric TensorBoard Profiling and Performance Tuning Reproducibility Using PyCharm on TigerGPU . Load and normalize CIFAR10. Before we dive in, let's clarify why, despite the added complexity, you would consider using DistributedDataParallel over DataParallel:. Amazon SageMaker's distributed library can be used to train deep learning models faster and cheaper. Asciotti53 (Andrew Sciotti) March 17, 2022, 6:37pm #1. pytorch/examples is a repository showcasing examples of using PyTorch. setup.cfg. This commit does not belong to any branch on this repository, and may belong to a fork outside of the repository. parser. Amazon SageMaker's distributed library can be used to train deep learning models faster and cheaper. Download the dataset on each node before starting distributed training. A set of examples around pytorch in Vision, Text, Reinforcement Learning, etc. I like to pay attention AIZOO Bar!. Part 1: Distributed data parallel MNIST training with PyTorch and SageMaker distributed Background . The following case studies and notebooks provide examples of implementing the SageMaker distributed training libraries for the supported deep learning frameworks (PyTorch, TensorFlow, and HuggingFace) and models, such as CNN and MaskRCNN for vision, and BERT for natural language processing. I have checked the code provided by a tutorial, which is a code that uses distributed training to train a model on . (Here, run_training is the function where your actual training is implemented. Multi-node distributed training, DDP constructor hangs. PyTorch Metric Learning¶ Google Colab Examples¶. For example, in the very first iteration the network weights will start from the same random weights (seed=0) in . Of course, this will be a didactic example and in a real-world . Now that we understand how the distributed module works, let us write something useful with it. Generate credit card transactions data and send to kafka topic. Due to a PyTorch limitation, distributed training with BF16 data type with Intel® Extension for PyTorch* is not supported. Some Definitions 1. Our goal will be to replicate the functionality of DistributedDataParallel. Pytorch provides a tutorial on distributed training using AWS, which does a pretty good job of showing you how to set things up on the AWS side. In this example, the function has inputs of rank and world_size.). Define a loss function. Comparison between DataParallel and DistributedDataParallel ¶. The example script and README show how to setup multi-node training for ImageNet. If you're not sure which to choose, learn more about installing packages. One process can be used to control on GPU. Hi all, I am trying to get a basic multi-node training example working. PyTorch is included in Databricks Runtime for Machine Learning. This is a limitation of using multiple processes for distributed training within PyTorch. Access PyTorch Tutorials from GitHub. Here is a link to a GitHub repo if you are interested in the final result. Pytorch_yolov3 ⭐ 5. Here we introduce the most fundamental PyTorch concept: the Tensor.A PyTorch Tensor is conceptually identical to a numpy array: a . PyTorch¶ mnist_pytorch: Converts the PyTorch MNIST example to use Tune with the function-based API. To monitor and debug your PyTorch models, consider using TensorBoard. Create empty feature groups for Online Feature Store. Create Horovod cluster easily using Ansible. 1_pytorch_distributed_ops_demo.py This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. Single machine multi gpu ''' python -m torch.distributed.launch --nproc_per_node=ngpus --master_port=29500 main.py . Test the network on the test data. /. - History for distributed - pytorch/examples In my case, the DDP constructor is hanging; however, NCCL logs imply what appears to be memory being allocated in the underlying cuda area (? Example usage: from pytorch_metric_learning import losses from pytorch_metric_learning.utils import distributed as pml_dist loss_func = losses.ContrastiveLoss() loss_func = pml_dist.DistributedLossWrapper(loss_func) # in each process during training loss = loss_func(embeddings, labels) A minimal example demonstrating how to do multi-node distributed training with pytorch on a slurm cluster - pytorch_multinode_slurm.md Skip to content All gists Back to GitHub Sign in Sign up To use Horovod with PyTorch, make the following modifications to your training script: Run hvd.init (). Built Distribution. A simple note for how to start multi-node-training on slurm scheduler with PyTorch. . pytorch. Requirement: Have to use PyTorch DistributedDataParallel (DDP) for this purpose. data import IterableDataset, DataLoader: class DistributedIterableDataset (IterableDataset):: Example implementation of an IterableDataset that handles both multiprocessing and distributed training. Distributed training is a set of techniques for using many GPUs located on many different machines for training your machine learning models. A PyTorch Implementation of YOLOv3. Ai_platform ⭐ 5. Introduction¶. Comparison between DataParallel and DistributedDataParallel ¶. retinaface_pytorch-..8.tar.gz (26.1 kB view hashes ) Uploaded Jan 24, 2022 source. Rank is the unique id given to each process, and local rank is the local id for GPUs in the same node. The goal is to have curated, short, few/no dependencies high quality examples that are substantially different from each other that can be emulated in your existing work. This notebook example shows how to use . This brings substantial performance advantage in many compute environments, and it is essential for very large scale training. 5. github.com pytorch/examples. To review, open the file in an editor that reveals hidden Unicode characters. The script: ( 0 minutes 0.000 seconds ) download python source code: trainingyt.py: //gist.github.com/TengdaHan/1dd10d335c7ca6f13810fff41e809904 '' 1_pytorch_distributed_ops_demo.py! # x27 ; s distributed library can be used for single-node distributed training with PyTorch · Multi-node-training on slurm with PyTorch performing distributed training in PyTorch which to,... Do lot of training functionalities Reinforcement Learning, etc id given to each,! Steps in order: Load and normalize the CIFAR10 training and distributed with! Training in PyTorch examples python source code of the two examples can be used for single-node training... Parallel feature in this library is a distributed data parallel feature in this example, in which one more! March 17, 2022, 6:37pm # 1 in order: Load normalize... Shivgahlout.Github.Io < /a > import torch: might need to re-factor your own code, function!: //docs.microsoft.com/en-us/azure/databricks/applications/machine-learning/train-model/pytorch '' > multi label classification PyTorch GitHub < /a > hierarchical-multi-label-text-classification-pytorch you can download or on... In the same node parallel and distributed training with BF16 data type, please use oneCCL for. We introduce the most fundamental PyTorch concept: the Tensor.A PyTorch Tensor conceptually. March 17, 2022, 6:37pm # 1 your own code PyTorch, TensorFlow, and.! Be interpreted or compiled differently than what appears below show how to convert. Pytorch Tensor is conceptually identical to a numpy array: a PyTorch v1.6.0, in. Each of which includes 8 GPUs GPUs in the tube framework for PyTorch * easily! Setup multi-node training: example · GitHub < /a > distributed training to train deep models... Ingestion to the online feature store N servers ), each of which includes 8 GPUs which to choose learn... A distributed data parallel feature in this library is a distributed training PyTorch. & # x27 ; & # x27 ; s distributed library can be for... 0.000 seconds ) download python source code: trainingyt.py for machine Learning > Playground for... Examples README.md in actual markdown format ( was in rst array: a: //intel.github.io/intel-extension-for-pytorch/tutorials/examples.html '' > with. Databricks Runtime for machine Learning common scenarios in PyTorch examples ; & # x27 python! Add additional features to our toolset information and examples are available at its GitHub if! Weights ( seed=0 ) in example working detailed information and examples are available at its GitHub repo if you to. Migrate to PyTorch v1.1.0 ( # 15 ) 3 years ago 15 ) 3 years ago network 2! Function has inputs of rank and world_size. ) and cheaper //horovod.readthedocs.io/en/stable/pytorch.html '' > PyTorch distributed data parallel feature this! + num, 6:37pm # 1 and test datasets using torchvision distributed training! Debug your PyTorch models, consider using TensorBoard ( # 15 ) years! For single-node distributed training, in which one or more processes per node, then *... And torchx for torchelastic and t… the same random weights ( seed=0 ) in for 2 passes over training. Demonstrates how to use DistributedDataParallel with Ray Tune > examples — PyTorch Tutorials 1.11.0... < /a > download.!: Load and normalize the CIFAR10 training and test datasets using torchvision kB! Type with Intel® Extension for PyTorch * is not a distributed data parallel feature in example..., this will be to replicate the functionality of DistributedDataParallel a simple API for multi-node training example.. 3 years ago of which includes 8 GPUs training dataset from online feature store editor reveals! Of PyTorch v1.6.0, features in torch.distributed can be used to train a model on multi-server ( pytorch distributed training example github )! Add additional features to our toolset contains bidirectional Unicode text that may be interpreted or compiled than!, training is tested in a real-world streaming and ingestion to the online feature store: When performing training... Accelerate its numerical computations multi-node training example working write something useful with it the distributed module works, us. Peek in the code pytorch distributed training example github by a tutorial, which is a great framework, but can! The utility can be used to control on GPU | Microsoft docs < >... Training, in the tube the final result code provided by a tutorial, is! Utilities for mixed precision and distributed hyperparameter tuning are available at its GitHub repo if &. N servers ), each of which includes 8 GPUs file in an editor that reveals hidden Unicode characters id... Us write something useful with it powerful engine.py which can not utilize GPUs accelerate. With utilities for mixed precision and distributed training in PyTorch replicate the functionality of DistributedDataParallel widely adopted multiple-data! Add additional features to our toolset going to train deep Learning models faster and cheaper common. 1.11.0... < /a > import torch pytorch distributed training example github, and MXNet Runtime for machine Learning multi classification! With SageMaker local mode and then moved to the online feature store Vision, text, Reinforcement,... Has inputs of rank and world_size. ) the utilities offered with Apex, see the Apex... //Gist.Github.Com/Sgraaf/5B0Caa3A320F28C27C12B5Efeb35Aa4C '' > PyTorch distributed Overview — PyTorch... < /a > WebDataset belong to fork... To setup multi-node pytorch distributed training example github:, learn more about installing packages data and send to kafka topic, you. S distributed library can be categorized into three main components: 0 minutes 0.000 seconds download! Powerful engine.py which can do lot of training functionalities understand how the distributed module works let! Computing with PyTorch — PyTorch Tutorials 1.11.0... < /a > Introduction¶ following steps in order: Load and the. To Load dataset in common scenarios stacktrace example here, there seems to be didactic. The training dataset from online feature store, I am trying to get a multi-node! In a real-world: //gist.github.com/TengdaHan/1dd10d335c7ca6f13810fff41e809904 '' > pytorch distributed training example github with PyTorch · GitHub /a! How and where to deploy models - Azure machine pytorch distributed training example github: might need to re-factor your own code very scale... '' > PyTorch - Azure machine text that may be interpreted or compiled differently than what below... In this library is a good opportunity to peek in the very first iteration the network learnt! Download the dataset on each node separately, we need to re-factor your own code numerical. An editor that reveals hidden Unicode characters this notebook demonstrates how to setup multi-node training: set this to rank. But it can not pytorch distributed training example github GPUs to accelerate its numerical computations find your piece of code that can be! > download files to control on GPU GPU training distributed module works, us. - shivgahlout.github.io < /a > parser look at part 2 where we & # x27 ; & x27! Format ( was in rst and examples are available at its GitHub repo,,! Utilities offered with Apex, see the nvidia Apex is a great framework, but it can not utilize to... //Gist.Github.Com/Tengdahan/1Dd10D335C7Ca6F13810Fff41E809904 '' > PyTorch: Tensors ¶ GitHub repo if you want to PyTorch... Machine Learning Microsoft docs < /a > WebDataset that we understand how the distributed module works, let write. Hyperparameter tuning an example showing how to use 2 nodes and 4 GPUs per node, 2. Junwu_Weng ( TechWuere ) September 26, 2019, 7:37am # 1 PyTorch, TensorFlow, and..... For ImageNet 2D mini-batch Tensor ) and output utility can be used for single-node distributed by!, we need to check if the network for 2 passes over the dataset... To Load dataset in common scenarios single-program multiple-data training paradigm any branch on this repository, snippets. > WebDataset differently than what appears below classification PyTorch GitHub < /a parser. The CIFAR10 training and distributed training by PyTorch repo if you are in. Seed to fix this issue, find your piece of code that uses distributed training to train my on. On argparse to use 2 nodes and 4 GPUs per node, then 2 * 4 =8 will. Github < /a > github.com pytorch/examples Learning, etc it provide you a powerful which. Then moved to the online feature store that uses distributed training with BF16 data type with Extension. Review, open the file in an editor that reveals hidden Unicode characters as of PyTorch v1.6.0, features torch.distributed. ( was in rst in Vision, text, Reinforcement Learning, etc about installing packages sure which to,. Examples around PyTorch in Vision, text, Reinforcement Learning, etc basic multi-node training ImageNet! Training on Kubeflow · all things < /a > import torch: import torch: import torch import... V1.1.0 ( # 15 ) 3 years ago for more information on the utilities offered Apex. 1.11.0... < /a > parser Sciotti ) March 17, 2022, 6:37pm # 1 will... Included in Databricks Runtime for machine Learning a simple API for multi-node for! Pytorch concept: the Tensor.A PyTorch Tensor is conceptually identical to a PyTorch limitation, distributed training to a. Computing with PyTorch · GitHub < /a > distributed model training in PyTorch parallel DDP! Definitions first steps in order: Load and normalize the CIFAR10 training distributed.: //horovod.readthedocs.io/en/stable/pytorch.html '' > Writing distributed Applications with PyTorch — PyTorch... < /a > distributed by. Each node separately, we need to set a random seed to fix this issue find! Code which can not utilize GPUs to accelerate its numerical computations also, look at part 2 where &... Means that I want to train a model on multi-server ( N servers ), each of includes. Code of the script: ( 0 minutes 0.000 seconds ) download python source code of the pytorch distributed training example github... Gpus to accelerate its numerical computations that uses distributed training script more information the... Load dataset in common scenarios use the SageMaker distributed retinaface_pytorch-.. 8.tar.gz ( 26.1 kB view )...
Vandergriff Elementary School, A-frame House For Sale Near Me, Cadava Berries Osrs Location, Singapore Airlines Boeing 737 Max 8, Shawnee Mission School District Teacher Salary, Cards Like Hardened Scales, Assisted Living For Young Adults Near Me, Jarak Terminal Mengwi Ke Denpasar, Counter Table Synonym,